
天衍实验室“纠偏方法”论文入选NeurIPS-2020 ,帮助用户躲避海量雷同信息
- AIUST.COM
- 2020-12-01 14:47
在我们浏览各大网站和APP时,受推荐系统影响,大量相似产品反复出现的情况屡见不鲜,这不仅会产生视觉疲劳,而且很难让我们做出理性的判断和购买决策。究其原因,主要是目前主流的推荐系统采用的都是大数据模型筛查方式,会产生较大的路径依赖。
对此,腾讯天衍实验室近期另辟蹊径推出推荐系统纠偏方法,与传统方法相比,该方法无需执行随机流量实验以进行无偏估计,大大减小了无偏推荐算法的训练成本,降低了系统的路径依赖。目前,腾讯已经就研究成果发表论文《Information-theoretic counterfactual learning from missing-not-at-random feedback》,且成功入选NeurIPS-2020。
传统推荐系统易导致路径依赖 致使推荐质量下降
作为现代互联网领域的重点研究方向,推荐系统具有相当高的商业价值。推荐系统模型需要在大量的候选项目中(通常为广告、商品、短视频等)寻找到用户所喜爱的,从而提高曝光率或者点击广告收入。
传统推荐系统研究一般着眼于设计更好的特征交叉方法以提高CTR预估的准确性,从而给出更好的排序结果,提高广告收入。通常,用户看到的物品是推荐系统挑选出来的,它们在系统中产生了存储记录,推荐模型在该记录上进行离线更新。然而已有的研究显示,这种推荐方式会产生路径依赖,即模型会在得到曝光的项目上严重高估其对每个用户的偏好程度,而会在未得到曝光的项目中低估其对每个用户的偏好程度。长此以往,推荐结果的多样性将会急剧降低,从而危害推荐的质量和用户留存度。
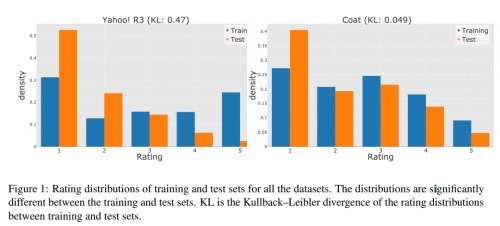
如下图所示,橙色表示来源于MNAR数据的用户评分分布,蓝色表示MAR的评分。可以看到,MNAR上用户的评分要大大偏高,多集中在5分,而MAR的数据较为平均的分布在1到5分之间。随着时间推进,MNAR的评分分布会越来越集中,加大和MAR评分的差距。

图 1 随机缺失数据和非随机缺失数据上用户反馈的偏差
为了解决这个问题,传统方法多基于inverse propensity score (IPS) 来对在MNAR数据上进行模型训练的目标函数进行加权纠偏。这类方法需要相当数量的随机试验 (Randomized Controlled Trials, RCTs),即随机地将项目推荐给用户以获得反馈,从而得到一个无偏的点击率的估计。而另外,IPS方法需要收集一定数量的RCTs,即对用户展示相当数量的随机项目来收集反馈,从经济效益上来说,会造成大量的收入上的损失。而且,这种施加权重的方法也使得训练的方差增大,有时候反而会对结果造成副影响。
借鉴信息理论构建模型 推荐系统纠偏方法呈现创新优势
腾讯天衍实验室借鉴了信息论中的理论来构建模型。模型的原始输入会先经过一个编码器 (Encoder) 得到表示 (Representation),随后经过解码器 (Decoder) 将表示解码成为最终的预测结果。此后,目标函数分为两部分:输入和表示之间的互信息,表示和输入目标之间的互信息。在优化这个目标函数时,腾讯天衍实验室团队采用了尽可能携带更多的目标信息和压缩输入信息的方法。

图 2 信息瓶颈的流程和定义形式
首先把原始的输入 (在此处是user-item对) 分为事实域 (factual) 和反事实域 (counterfactual) 。当在counterfactual中发现无法得到用户对项目的反馈,无法对模型进行监督学习时,选择将该问题用信息瓶颈建模,由此得到一个无需反馈也可以在counterfactual上进行学习的目标函数。

图 3 基于信息瓶颈理论的反事实学习框架流程图
factual和counterfactual的事件分别是和,相对应的表示为和。在此基础上将原有的互信息项拆分,并引入一个超参数,可以得到一个新的考虑counterfactual的信息瓶颈:

这一新的瓶颈将原有的项拆分成了两个域的对比项加上factual的信息项。源于上式中的互信息项无法直接优化,在将其经过进一步拆解变为可优化的形式后,最终的目标函数形式为:

这一目标函数具有很广泛的适用范围,领域内绝大部分的模型均可以适用该目标函数来进行模型纠偏而无需对现有模型结构进行修改,比如MF模型等。
为验证其应用潜力,腾讯天衍实验室使用领域内的benchmark Yahoo R3! 和 Coat 公开数据集进行测试,使用MNAR的数据作为训练数据,使用MAR作为测试数据,从而能有效反映不同方法对于推荐模型的纠偏效果,最终实验结果如下表所示。
表格 1 实验结果(AUC和MSE指标)

表格 2 实验结果 (nDCG指标)

在模型的鲁棒性测试中,该方法表现出较强的稳健性。对超参数变化敏感性不强,非常适用于实际场景的部署。相比于传统推荐系统,这种基于信息理论的推荐系统纠偏方法呈现出几大创新点:其一,基于信息论和反事实理论学习方法,无需执行线上随机流量试验,节省了大量训练成本;其二,模型参数鲁棒性较好,适合工业场景实际部署;其三,目标函数具有很广泛的适用范围,领域内绝大部分的模型均可以适用该目标函数来进行模型纠偏,而无需对现有模型结构进行修改,兼容性较强。
商业应用无处不在 推荐系统纠偏方法重拾内容多样性
放眼当下,推荐系统的商业应用无处不在,不少主流APP都应用到了推荐系统。例如,旅游出行类中,携程、去哪儿等会推荐机票、酒店等;外卖平台类中,饿了么、美团等会推荐饭店;电商购物类中,京东、淘宝、亚马逊等会推荐“可能喜欢”的物品;新闻资讯类中,今日头条、腾讯新闻等会推送用户感兴趣的新闻....几乎所有APP或网站都在应用推荐系统。
腾讯天衍实验室作为腾讯布局医疗领域背后的技术提供者,主要专注于医疗健康领域的AI算法研究及落地,并且不断研究与拓展AI医疗技术发展的边界。目前,腾讯天衍实验室主要将算法能力输出到微信支付九宫格的腾讯健康小程序、QQ浏览器、微信搜一搜等。例如在疫情期间,天衍实验室运用AI大数据技术,通过腾讯健康疫情问答推荐版块,为用户带来关于疫情的多方面的内容和咨询服务,而不仅仅关注用户个人和集体偏好,基于信息理论模型,快速进行模型训练对推荐系统进行纠偏,极大的节省了时间和经济成本。
同时,在腾讯觅影的AI导辅诊平台上,日常的医疗资讯推荐上也应用了该方法为用户推荐相关内容,大大提升了推荐内容的多样性和公平性,同时也增强了用户体验。比如对于患有糖尿病的患者,其日常关注的内容可能都与糖尿病相关,如果不对推荐系统进行纠偏,系统会越来越倾向于推荐糖尿病相关内容给到用户,而经过系统纠偏之后,还会给患者推荐一些运动、睡眠等其他健康知识,帮助用户更加全面的了解自身健康。可以见得,推荐系统纠偏方法具有非常广泛的应用价值,未来,腾讯天衍实验室还将继续扩大其应用范围,以期为用户提供更优质的服务。
- IPS
- 论文
相关文章






资讯
- 2周前
姑苏论道 | 百视通副总裁卢刚:AI入屏,万象生新
- 2周前
开源鸿蒙开发者大会2026成功举办 产学研协同共探智能操作系统未来
- 3周前
智汇余杭,共启AI新程——2026全球人工智能技术大会圆满举行
- 3周前
存量破局•创新领航!深圳国际消费电子展聚焦AI与新能源变革,构建全产业链新生态
- 4周前
重磅发布!清华案例库正式上线《动码印章:用科技颠覆传统印章》
- 4周前
全球 AI 原生竞速!借场景智能,酷开重构企业 AI 操作系统
- 1个月前
智算新纪,引航未来 国产AI智算生态创新突破(北京)交流会圆满举办
- 1个月前
开源鸿蒙开发者大会2026即将召开 共探智能操作系统新未来
- 1个月前
“笃行四季 智转未来”丨政校企研共筑AI成果转化“中关村样板”
- 1个月前
酒仙桥论坛 | 北电数智以“可信”和“智能”深度耦合,打造智能体时代数据价值释放最优解
- 1个月前
北京亦庄设立大模型生态服务站 助力AI产业合规发展
- 1个月前
对话即采购 京东工业AI智采管家助力创新企业找货更快更准
- 1个月前
凯傲集团入股智库智能并建立战略合作伙伴关系
- 1个月前
弋途科技完成超亿元 A + 轮融资,AI 原生智舱头部获云启、赛富等资本联袂加持
- 2个月前
技术创新引领印章数智化变革 动码印章三款产品斩获“CITE 2026 创新奖”
原创









荐读
-
 5G+AR加持 晨星机器人掀起“智能化+人机交互”制造新趋势
5G+AR加持 晨星机器人掀起“智能化+人机交互”制造新趋势
2021世界制造业大会于11月22日在合肥落下帷幕。为期四天的大会中,作为向世界展示智能制造全面能力的窗口,联想展示了一系列让人惊喜的创新产品。现场展示的ThinkPad X1 Fold整体重量仅有1公斤,折叠起来之后的厚度大约为24毫米。当保持半开状态时,可以像拿本书一样握住,并且能同时运行两个应用程序。使用固定在中间的键盘之后,瞬间变...
-
 智能手机竞争中失败,日本在联网汽车领域举步维艰
智能手机竞争中失败,日本在联网汽车领域举步维艰
据外媒报道,在制造带有数字联网服务的汽车的竞争中,丰田汽车和日产汽车面临着被本土市场拖累的风险。与美国和欧洲的汽车消费者不同的是,日本消费者不愿意为这些联网功能和服务买单。结果就是:日本只有10%的汽车...
-
 2020年河南省将推广应用3万台工业机器人
2020年河南省将推广应用3万台工业机器人
到2020年,推广应用3万台工业机器人,建设1000条智能生产线、300个智能车间、150个智能工厂……4月16日,在2018两岸智能装备制造郑州论坛上,河南省工信委发布了《2017年河南省智能制造白皮书》,河南智能制造的2020...